Kas yra Mixture of Experts ir kodėl tai keičia DI žaidimo taisykles
·
DeepSeek V4 turi 1.6 trilijono parametrų, bet naudoja tik 49 mlrd. vienu metu. GPT-5.5 veikia panašiu principu. Gemini irgi. Kaip tai įmanoma?
Atsakymas: Mixture of Experts. Arba trumpai, MoE.
Ir tai viena svarbiausių priežasčių, kodėl šiuolaikiniai DI modeliai tapo tokie greiti ir pigūs.
Paprasta analogija
Įsivaizduok ligoninę. Joje dirba 100 gydytojų: kardiologai, chirurgai, neurologai, dermatologai. Kai ateini su skaudančia širdimi, tavimi užsiima ne visi 100, o tik 3-4 kardiologai. Likusieji laukia savo pacientų.
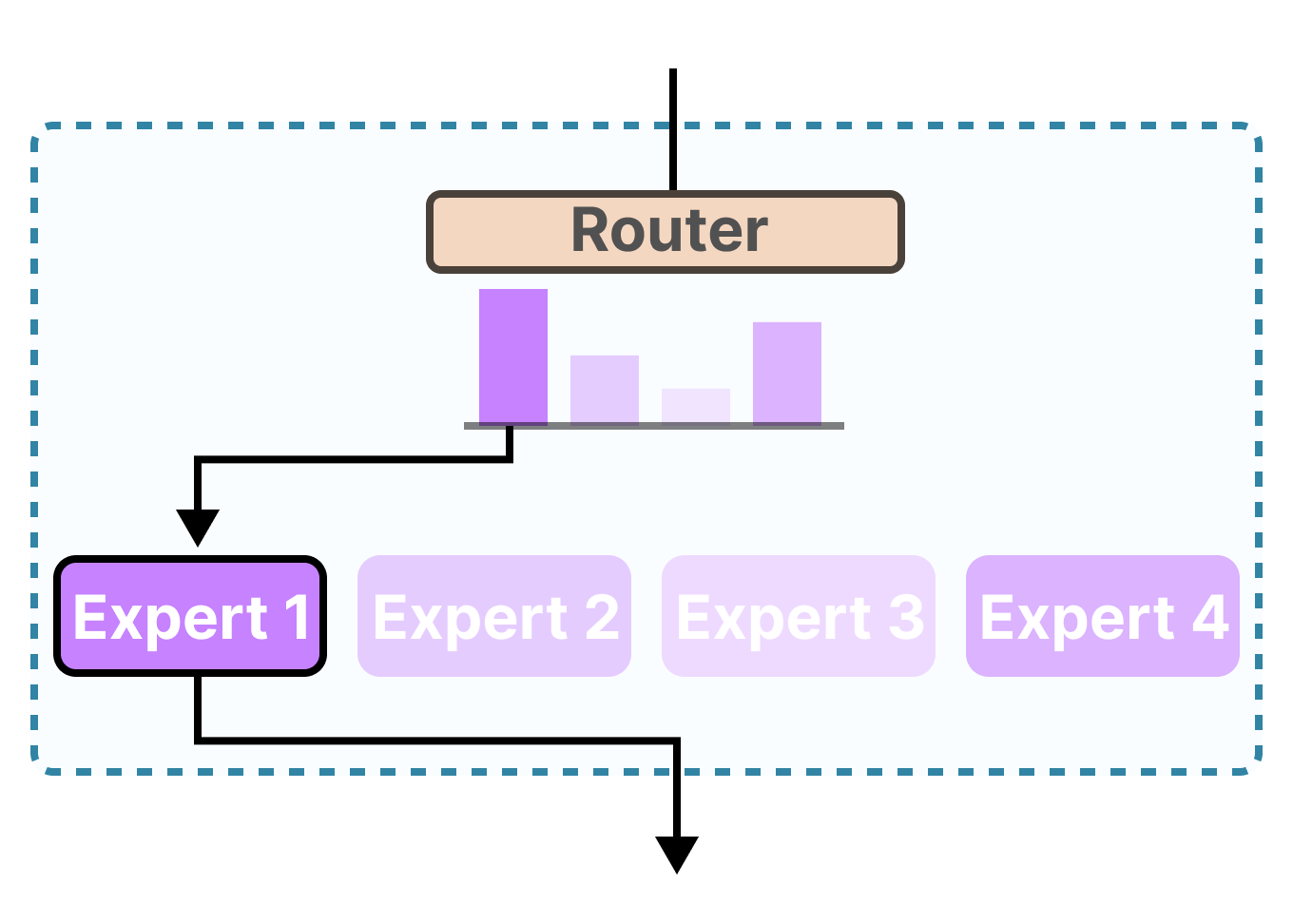
MoE veikia identiškai. Modelis turi šimtus ar tūkstančius „ekspertų” (tai specializuoti neuroninių tinklų blokai), bet kiekvienai užklausai aktyvuoja tik kelis iš jų. Specialus komponentas, vadinamas maršrutizatoriumi (router), nusprendžia, kurie ekspertai geriausiai tinka konkrečiai užduočiai.
Kodėl tai svarbu
Tradicinis modelis naudoja visus savo parametrus kiekvienam žodžiui. Tai kaip ligoninė, kurioje visi 100 gydytojų aptarnauja kiekvieną pacientą. Neefektyvu. Brangu. Lėta.
MoE leidžia turėti milžinišką modelį su trilijonu parametrų, bet naudoti tik nedidelę dalį bet kuriuo momentu. Rezultatas:
Mažesnis energijos suvartojimas. Greitesni atsakymai. Pigesnė kaina. O kokybė lieka panaši į pilno modelio.
Jei neuroniniai tinklai tau dar naujiena, pradėk nuo čia ir grįžk prie šio straipsnio.
Kas yra tie „ekspertai”
Ekspertas MoE kontekste nėra žmogus. Tai feed-forward neuroninio tinklo blokas, kuris specializuojasi tam tikrose užduotyse. Vienas ekspertas gali geriau apdoroti matematiką, kitas kalbos niuansus, trečias kodavimą.
Maršrutizatorius (dar vadinamas vartininku, gating network) gauna įvesties duomenis ir apskaičiuoja tikimybes, kurie ekspertai geriausiai susidoros su konkrečia užduotimi. Paprastai aktyvuojami 2-8 ekspertai iš kelių šimtų.
Realūs pavyzdžiai
DeepSeek V4-Pro: 1.6 trilijono parametrų, bet tik 49 mlrd. aktyvūs. Tai reiškia, kad modelis naudoja vos 3% savo galios bet kuriuo momentu. Likę 97% ilsisi.
Google Gemini naudoja panašią architektūrą. Visi didieji kalbos modeliai (LLM) juda šia kryptimi, nes alternatyva, naudoti visus parametrus, tampa per brangi.
Trūkumai
MoE nėra tobula. Treniravimas sudėtingesnis, nes reikia išmokyti ir ekspertus, ir maršrutizatorių. Modelio bendras dydis diske lieka didelis, nors aktyvių parametrų mažai. Ir kartais maršrutizatorius priima ne pačius geriausius sprendimus, nukreipdamas užklausą ne tam ekspertui.
Bet privalumai gerokai viršija trūkumus. Todėl 2026 metais praktiškai visi nauji DI modeliai naudoja MoE.
Daugiau DI terminų ir sąvokų rasite mūsų žodyne.
Kitą kartą, kai kas nors sakys „modelis turi trilijoną parametrų”, žinosi, kad realybė sudėtingesnė. Ir įdomesnė.


